Introduction: the mystery bill moment
A product team ships a feature on Friday. By Monday, finance has a panic email: cloud spend spiked 40% over the weekend. No one is sure why. Sound familiar?
That chaos is exactly what service management in cloud computing is built to prevent. It blends proven ITSM disciplines (incident, change, problem, request, service catalog) with modern cloud ops (SRE, FinOps, IaC, AIOps) so you deliver reliable services and keep costs and risks in check. With cloud spend projected to reach around $723B in 2025 and cost control still a top challenge, getting service management right is now a board-level priority.
Have you ever noticed how outages, surprise bills, and security gaps often share one root cause—unclear ownership and weak processes? This guide shows exactly how to fix that.
What is service management in cloud computing?
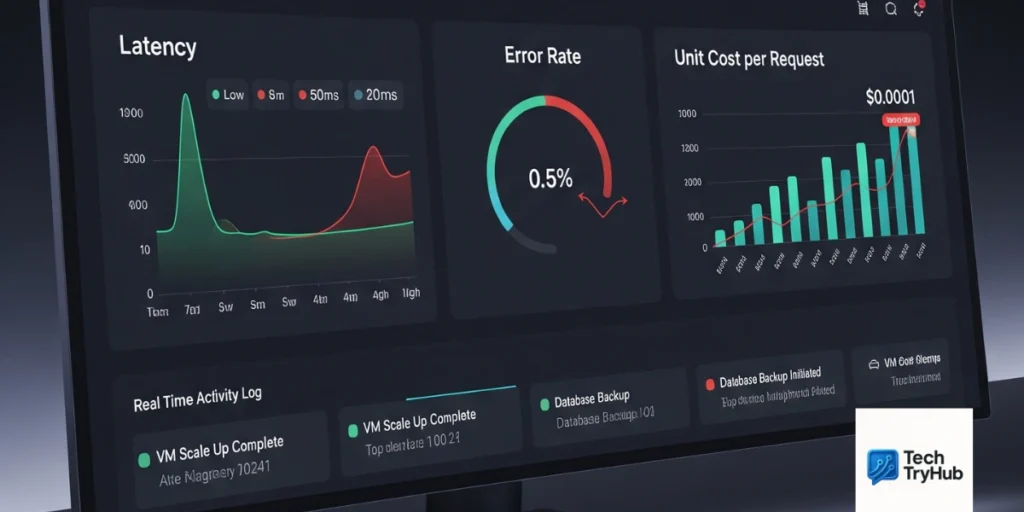
Context: In the cloud era, services are dynamic: autoscaling, ephemeral, and multi-region. Traditional ITSM still matters—but it needs cloud-native upgrades.
Explanation: Service management in cloud computing is the set of people, processes, and platforms that plan, deliver, operate, and continually improve cloud services. It uses ITIL 4 as a backbone (value streams, practices, continual improvement), aligns with cloud adoption frameworks, and integrates SRE, DevOps, and FinOps for financial accountability.
Example: Your “Payments API” is a service with an SLO, an on-call rotation, cost and error budgets, change policies, and a dashboard that shows health and unit cost per 1,000 calls.
Mini takeaway: Treat each cloud workload as a product with clear owners, SLOs, and cost telemetry.
Key takeaways
- Cloud service management = ITIL 4 + SRE/DevOps + FinOps.
- Manage services as products (SLOs, SLAs, cost per unit).
- Align process, tooling, and finance with your delivery teams.
Why now: trends that raise the bar
Context: Cloud adoption has matured—from experiments to mission-critical platforms.
Explanation:
- Multi-cloud and SaaS sprawl mean more vendors, APIs, and bill lines to govern. Flexera reports 89% of enterprises use multi-cloud and more are adopting multi-cloud security and FinOps tools.
- Costs are under the microscope. FinOps Foundation shows cost optimization, waste reduction, and commitment management are top priorities in 2024–2025.
- Budgets are surging with AI. Analyst views show sustained spend growth through 2025, much of it tied to AI/GenAI services, which magnify both value and waste if unmanaged.
Example: A company launches a GenAI feature on a managed inference service. Without guardrails (quotas, autoscaling policy, and request caps), nightly batch jobs double the bill.
Mini takeaway: As complexity and spend rise, service management is your safety rail.
Key takeaways
- Multi-cloud is the norm; governance and visibility must keep up.
- FinOps priorities: reduce waste, manage commitments, improve showback/chargeback.
- AI accelerates value and potential overspend; put controls in design.
Core building blocks (ITIL 4, SRE, and FinOps working together)
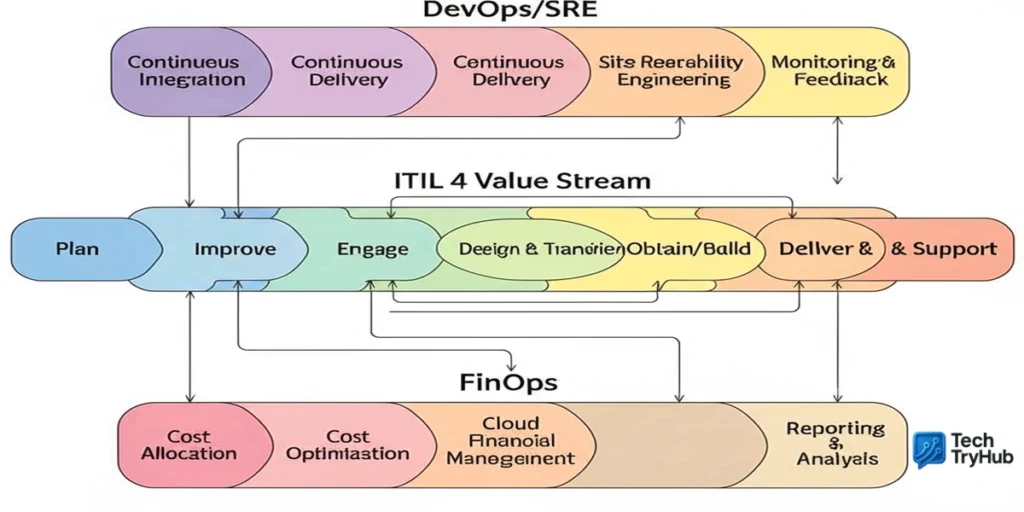
Context: Frameworks overlap—use them together, not in silos.
Explanation:
- Service catalog & request management: Standardize what teams can consume (e.g., “Gold API template,” “Managed PostgreSQL”). Tie every item to controls: limits, tags, SLOs, backups.
- Change enablement: Replace weekly CABs with safe, frequent, automated changes (peer-reviewed PRs, progressive delivery). AWS frames ITIL 4 as compatible with cloud adoption patterns.
- Incident & problem management: SRE-style incident response with blameless postmortems and error budgets that inform release pace.
- Observability & AIOps: Metrics, logs, traces; anomalies auto-triaged to reduce MTTR.
- FinOps (“cost as a KPI”): Tagging, showback/chargeback, commitment management (SPs/RIs/Savings Plans), unit economics in dashboards. FinOps Foundation surveys highlight priorities shifting toward waste reduction and better attribution.
Example: A platform team publishes Terraform modules (with golden guardrails) into a self-service catalog; changes are deployed via GitOps; costs show up in the same Grafana board as latency.
Mini takeaway: Integrate process with pipelines and dashboards so governance happens automatically.
Key takeaways
- Bake controls into templates, not after the fact.
- Treat cost and reliability as first-class SLOs.
- ITIL 4 practices map cleanly to cloud delivery patterns.
SLAs, SLOs, and “cost SLOs”: setting the right targets
Context: Availability alone doesn’t define success.
Explanation:
- SLA: Contract with customers (e.g., 99.9% uptime).
- SLO: Internal target with error budget (e.g., 99.95% over 30 days).
- Cost SLO: Target unit cost (e.g., “≤ $0.15 per 1,000 requests”). Teams monitor variance and trigger optimizations when breached.
- Attribution: Map cost to services, features, and customers; many orgs now use FinOps platforms + native tools to improve tagging and allocation.
Example: An e-commerce API has a 250ms p95 SLO and $0.12/1k request cost SLO. A new feature raises p95 to 400ms and cost to $0.20; the team rolls back and optimizes queries.
Mini takeaway: Pair reliability SLOs with cost SLOs to balance experience and economics.
Key takeaways
- SLAs are promises; SLOs are engineering levers.
- Add unit-cost SLOs to align performance with spend.
- Accurate cost attribution enables meaningful cost SLOs.
Governance that doesn’t slow you down
Context: Legacy governance can block progress; cloud needs lightweight, automated controls.
Explanation (with examples):
- Guardrails-by-design: Use IaC modules that enforce encryption, tagging, network policies, backup and retention by default.
- Change policy tiers: Low-risk, reversible changes flow automatically; higher-risk changes require peer review and progressive rollouts. This aligns with ITIL 4’s value-stream mindset and AWS change enablement guidance.
- FinOps in design (“shift-left cost”): Include price estimates, commitments, and autoscaling policies in ADRs (architecture decision records). Industry commentary shows firms that treat cost as a design factor cut waste significantly.
Mini takeaway: Move governance into templates, pipelines, and ADRs—not meetings.
Key takeaways
- Automate policy enforcement; don’t rely on manual gates.
- Right-size change controls to risk and blast radius.
- Consider cost at design time to avoid waste.
Tooling landscape: ITSM, cloud-native, and FinOps platforms
Context: You’ll need a small, well-integrated stack.
Explanation:
- ITSM/ESM platforms (e.g., ServiceNow, Jira Service Management, Freshservice) manage requests, incidents, change, CMDB/CSDM. Independent roundups highlight these for 2025 buyers.
- Cloud-native ops: Observability (CloudWatch/Cloud Logging/Azure Monitor + OpenTelemetry), runbooks, feature flags, incident tooling.
- FinOps & cost optimization: Native cost explorers + third-party platforms; 2024 reports show many enterprises adopting multi-cloud FinOps tools.
Mini takeaway: Choose tools that integrate with Git, IaC, and your incident/alerting pipeline.
Key takeaways
- Pick an ITSM core, augment with cloud-native ops. Combine native billing with specialized FinOps platforms.
- Integration beats feature checklists.
A practical operating model (RACI, runbooks, and dashboards)

Explanation (step-by-step):
- Define services and owners: Each service has a product owner, tech owner, and on-call.
- Create golden templates: Publish Terraform/ARM/CDK modules and pipeline templates with guardrails.
- Publish a service catalog: Only approved patterns are requestable; automate provisioning and tagging.
- Set SLOs and playbooks: Reliability + cost SLOs with on-call runbooks.
- Instrument everything: Unified dashboards showing latency, error rate, saturation, and unit economics.
- Continuous improvement: Monthly ops reviews; apply problem management and postmortem actions.
- FinOps cadence: Forecasting, commitment management, right-sizing, and waste hunts (unused volumes, underutilized instances). FinOps surveys emphasize these as core annual priorities.
Mini takeaway: Your “cloud operating model” is just clear ownership + paved-road templates + visible KPIs.
Key takeaways
- Make the paved road the fastest road.
- Put SLOs and cost in the same view.
- Turn retros into backlog items.
Comparison table: ITSM vs. Cloud Service Management vs. FinOps
| Dimension | Traditional ITSM | Cloud Service Management | FinOps |
| Primary goal | Restore service, manage requests | Reliability, speed, and safe change at scale | Align cloud spend to business value |
| Cadence | Tickets, scheduled CABs | Event-driven, automated, GitOps | Monthly/quarterly cost cycles + real-time alerts |
| Scope | Incidents, changes, problems | SRE practices, IaC, observability, SLOs | Tagging, showback/chargeback, commitments, unit cost |
| Success metrics | MTTR, SLA compliance | SLOs, error budgets, change failure rate | Cost per unit, % waste, forecast accuracy |
| Tooling | ITSM platforms | Cloud monitors, APM, runbooks | Native billing + FinOps platforms |
Mini takeaway: You need all three, tightly integrated.
10 cloud service management best practices (with “why it matters”)
Context: Start small, then mature.
- Define services before resources. Name owners, SLOs, and cost KPIs first; provision later.
- Build a self-service catalog. Standardize secure templates; accelerate delivery and compliance.
- Adopt change automation. CI/CD + progressive delivery (feature flags, canaries) aligns with modern ITIL 4 guidance.
- Instrument for reliability and cost. One dashboard; no silos.
- Shift-left cost. Run price estimates in design; commit to Savings Plans/RIs with engineering input (a growing FinOps focus.
- Right-size relentlessly. Rightsize VMs/DBs, clean idle volumes/IPs.
- Use error budgets to control release pace. Data, not opinion.
- Classify data and automate backups/retention. Templates enforce compliance.
- Document runbooks. Reduce cognitive load in incidents.
- Hold monthly ops + FinOps reviews. Tie postmortems and cost outliers to action items. Industry data shows adoption of multi-cloud security/FinOps tools to support this rhythm.
Key takeaways
- Standardization drives speed and safety.
- Combine SRE and FinOps guardrails.
- Review and improve every month.
Real-world pitfalls (and how to avoid them)
Context: Most failures are predictable.
Explanation:
- Tagging debt: If resources aren’t tagged by owner/service/env, cost attribution and incident response both suffer. Fix with policy-as-code and drift detection.
- Change friction: Over-centralized CABs slow delivery. Move to risk-based, automated approvals as AWS change-enablement suggests
- The mystery bill: Lack of unit economics and commitments; FinOps reports stress managing commitments and reducing waste in 2024.
Mini takeaway: Preventable problems vanish when you codify standards and treat cost like a reliability objective.
Key takeaways
- Enforce tags automatically
- Replace one-size-fits-all CABs with risk-based pipelines.
- Watch waste and commitments constantly.
Quotes & insights you can use
- “ITIL 4 provides a solid foundation for defining and maturing cloud capabilities,” and aligns with AWS’s Cloud Adoption Framework—useful when you’re mapping ITIL practices to cloud delivery.
- Analysts expect public cloud spend to hit ~$723B in 2025, keeping pressure on governance, FinOps, and efficient operations.
- 2024 enterprise surveys show multi-cloud and FinOps tool adoption keep rising—proof that financial and security operations are now shared responsibilities across teams.
Implementation roadmap (90 days)
Foundations : Days 1-30
- Define 10–20 top services, owners, and SLOs (reliability + unit cost).
- Create golden Terraform/ARM/CDK modules: VPC/VNet, database, container service, serverless.
- Enforce org-wide tags and guardrails (encryption, backups) via policy-as-code.
Operate & Observe : Days 31-60
- Publish a service catalog in your ITSM with automated provisioning.
- Stand up dashboards for latency, error rate, saturation, unit economics, and commitments.
- Pilot risk-based change automation (canary, blue-green, flags).
Optimize & Govern : Days 61-90
- Launch monthly Ops + FinOps review: rightsizing, waste hunts, commitment planning.
- Introduce showback/chargeback and cost SLOs for two critical services.
- Run game-days for incident response and rollback drills.
Key takeaways
- Start with a few services; expand once patterns work.
- Make the service catalog your paved road.
- Pair SRE rituals with a FinOps cadence.
Conclusion & CTA
Service management in cloud computing is how you turn cloud from “mystery bill and midnight pages” into a predictable, high-quality, cost-aware platform. Use ITIL 4 as your backbone, adopt SRE for reliability, and embed FinOps so cost becomes a design constraint, not a surprise. Start with a few critical services, publish golden templates, and review SLOs and unit costs every month.
If this helped, share the post and check out our guides on SLAs/SLOs and FinOps for engineers to go deeper. Your future self (and finance team) will thank you.
FAQ: service management in cloud computing
Q1. What is service management in cloud computing?
It’s how teams plan, deliver, and run cloud services using ITIL-aligned practices plus SRE/DevOps and FinOps to keep services reliable and costs controlled.
Q2. How is it different from traditional ITSM?
Cloud service management emphasizes automation, IaC, observability, and cost attribution, not just ticket workflows and SLAs. It integrates with pipelines and cloud platforms.
Q3. Which metrics should we start with?
Pick 2–3 SLOs (availability, latency) and a unit-cost metric (e.g., cost per 1,000 requests). Monitor all in one dashboard and review monthly.
Q4. Do we need FinOps if finance already watches spend?
Yes—FinOps brings engineers into cost decisions, adds tagging/attribution, and manages commitments and waste reduction as an operational practice.
Q5. Which tools are best?
Choose an ITSM core (ServiceNow, Jira Service Management, Freshservice), integrate with your cloud monitors/APM, and add a FinOps platform or native billing tools.
Q6. How do we avoid slowing down engineers with governance?
Move guardrails into templates and pipelines (policy-as-code, golden modules, automated approvals) and use risk-based change policies.
Q7. What about multi-cloud?
Standardize patterns (network, identity, tagging), use a central service catalog, and rely on multi-cloud security and FinOps tooling where it makes sense.